Comunicación presentada al V Congreso Smart Grids:
Autores
- Sergio Bustamante González, Responsable de Medida, Viesgo Distribución
- Rafael Minguez Matorras, Responsable de Innovación, Viesgo Distribución
- Hans Bludszuweit, Experto Tecnológico Estudios de Red y Smart Grids, Fundación CIRCE
- Laura Giménez de Urtasun, Directora Estudios de Red y Smart Grids, Fundación CIRCE
Resumen
El Smart Meter como elemento clave de las Redes Inteligentes de BT así como las técnicas Big Data y Data Analytics están posibilitando un cambio de enfoque en la detección de pérdidas no técnicas, pasando del modelo de gestión correctivo al preventivo. En este artículo se describirá un proyecto de aplicación de estas técnicas a las redes BT de Viesgo a través del Balance Energético en BT, implementado en la plataforma Big Data IDbox. Se requiere del despliegue de contadores en todas las instalaciones de BT incluyendo un totalizador por sub-redBT. En el proyecto se desarrollan algoritmos de Data Analytics que procesan la información identificando patrones en las curvas de pérdidas que facilitan la detección automatizada de anomalías. Aunque el proyecto aún no ha finalizado los primeros resultados son alentadores.
Palabras clave
Big Data, Data Analytics, Pérdidas no Técnicas, Smart Meter, Balance Energético, Baja Tensión
Introducción
La reducción de las pérdidas energéticas ha supuesto, históricamente, uno de los principales focos de atención de las empresas de distribución de energía eléctrica [1]. En este sentido, Viesgo Distribución ha desarrollado un proyecto para dar respuesta a la necesidad de cambio en la forma de gestionar las pérdidas no técnicas en las redes de distribución en BT, modernizando los métodos de trabajo gracias a las nuevas herramientas disponibles y al despliegue masivo de contadores inteligentes [2]. Las pérdidas no técnicas son ajenas a la distribución o transformación de la energía eléctrica y por lo tanto son susceptibles de eliminación. Para ello es necesario establecer unos métodos de detección que tradicionalmente se han basado en inspecciones in situ de los equipos de medida e instalaciones de conexión a la red. Este tipo de campañas de detección se han demostrado poco eficientes ya que consumen gran cantidad de recursos con resultados ciertamente discretos. Además, la detección por el método tradicional suele ser tardía y provoca un efecto correctivo en los procesos de facturación y liquidación de la energía en el mercado e implica, en muchas ocasiones, a los agentes comercializadores en el proceso de regularización. Cuando las pérdidas se producen en instalaciones sin contrato suelen ser necesarios esfuerzos adicionales en la gestión del cobro llegándose incluso a la vía judicial.
Las Redes inteligentes de Baja Tensión donde el Smart Meter adquiere un papel decisivo, las plataformas Big Data y el Data Analytics, están posibilitando la detección precoz de las pérdidas no técnicas, dando un enfoque preventivo al proceso que minimiza las pérdidas y hace innecesaria, en muchas ocasiones, la facturación complementaria, así como el resto de actividades de regularización, redundando todo ello en la eficiencia de operativa [3, 4].
Se podrá trabajar de esta nueva manera si se dispone de redes completamente equipadas con Smart Meters y de soluciones informáticas capaces de determinar de forma horaria las pérdidas energéticas. En este proyecto se han aplicado algoritmos avanzados a una muestra de clientes pertenecientes a una red real de 700.000 puntos de suministro repartidos en 12.000 sub-redes que han permitido localizar eventos significativos o patrones preestablecidos en las curvas de pérdidas, que han puesto de manifiesto la existencia de anomalías y por tanto la bondad de las soluciones adoptadas.
Balance energético en baja tensión
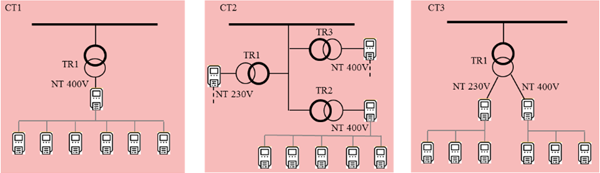
La herramienta que ha desarrollado Viesgo para realizar el estudio energético de las redes de BT es el Balance BT (BBT). Para su aplicación a un entorno real la red eléctrica en estudio se divide en tantas sub-redes como agrupaciones de Centro de Transformación (CT), Transformador de potencia MT/BT (TR) y Nivel de Tensión (NT), existan. El BBT también es capaz de crear supra agrupaciones a nivel de Municipio, Provincia y Empresa, tal como se observa en la Figura 1.
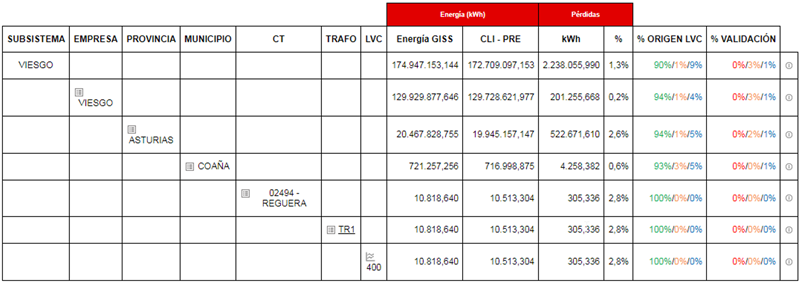
De cada una de las sub-redes o supra agrupaciones se obtiene el valor de la medida o suma de medidas registradas por los equipos instalados en el lado de BT de los transformadores de potencia MT/BT (Energía GISS) y la medida agregada de los clientes conectados a esa subred (CLI-PRE).
El sistema, así mismo, calcula y representa gráficamente la curva de pérdidas asociada a cada sub-redo el valor agregado de las mismas para cada supra agregación. En todos los cálculos el sistema realiza los saldos de energía entre las entradas producidas por los generadores en BT y las salidas correspondientes a los consumos de clientes.
Metodología de detección de pérdidas no técnicas
El método aplicado se describe en la literatura como detección de fraude basada en clasificación y consiste según [5] en los procesos representados en la Figura 3. Así. el proyecto se ha dividido en 5 fases: (i) Segmentación de clientes, (ii) Obtención de patrones de fraude, (iii) Desarrollo de algoritmos, (iv) Prueba piloto, (v) Plan de implementación.

Segmentación de clientes
En un primer paso, se realizó una clasificación de todos los clientes conectados a la red de VIESGO, basado en la información descriptiva existente tal como la actividad (según código CNAE), tarifa y potencias contratadas o consumo medio diario (entre otras). El objetivo fue crear un repositorio donde los clientes estuviesen clasificados según una serie de propiedades comunes, que pudiesen ayudar en la identificación del origen de las anomalías detectadas. Como resultado de este ejercicio, los aproximadamente 700.000 clientes agruparon en 270 segmentos. Como se puede observar en la Tabla I, la gran mayoría de los clientes (CUPS) se concentran en el grupo residencial representando más del 85% del total. Esta fase cubre preprocesamiento y extracción de características del esquema de la Figura 3.

La segmentación de los clientes permitió crear patrones de consumo típicos, asignando un patrón a cada segmento para cada mes del año. Por otro lado, se consultó esta clasificación para la selección de los clientes del piloto, realizada sobre los históricos del 10% de los clientes, comprobándose que la selección era representativa respecto a los segmentos creados.
Obtención de patrones de fraude
El segundo paso también es parte de la extracción de características y consistió en la creación de un repositorio de patrones típicos de fraude. Para ello se estudió una muestra de casos representativos detectados en la red de Viesgo entre 2015 y 2018, analizando los patrones observados en la curva de pérdidas en el BBT. En total se analizaron aproximadamente 700 casos de los cuales se extrajeron unos 100 patrones típicos. A través del CUPS de cada caso, cada patrón está relacionado con un segmento, que se obtuvo en el paso anterior. Hay patrones similares que se han observado en varios casos, por lo cual es posible que un patrón se clasifique como típico para más de un segmento. Por ejemplo, un patrón de calefacción en doble acometida puede darse en hogares con diferentes características.
Desarrollo de algoritmos
Clústering con k-means
El algoritmo empleado para crear y reconocer los patrones es el bien conocido “k-means” [6], que permite clasificar curvas de carga similares en clústeres de forma muy eficiente. Los patrones típicos se obtienen aplicando el algoritmo k-means sobre las curvas de carga de los casos reconocidos. Para obtener los patrones típicos, se clasificaron un total de 220.000 curvas diarias pertenecientes a unos 700 CUPS distintos, agrupando las curvas en 250 clústeres. De esta forma, se captan patrones similares en CUPS distintos. Cada clúster representa un patrón, pero debido al ruido en los datos, no todos los patrones que se obtienen con k-means son aplicables directamente. Es necesario filtrar los clústeres resultantes según una serie de criterios:
- Potencia media muy baja (< 5kW): Pérdidas muy bajas que se pueden confundir con las pérdidas técnicas
- Potencia máxima muy elevada (> 1000 kW): Error de medida
- Número elevado de CUPS (> 50): Agrupación de curvas similares, pero no distintivos
- Pocas curvas agrupadas (<10): Patrón no repetitivo (valores atípicos)
- Distancia media elevada (> 1 p.u.): Gran variedad dentro del clúster (mucho ruido de datos)
Tras el filtrado, quedaron 101 patrones que se consideraron para su implementación en el algoritmo de detección de patrones de fraude. En la Figura 4 se muestra un ejemplo de un patrón concreto. En este clúster se agruparon 106 curvas de carga diarias (24 h) procedentes de 5 CUPS distintos. Se observa cierto ruido en los datos, pero se reconoce un perfil claro de consumos domésticos con una punta al mediodía y otra por la noche. La curva negra es el centroide del clúster y representa el patrón que se ha creado en este clúster.
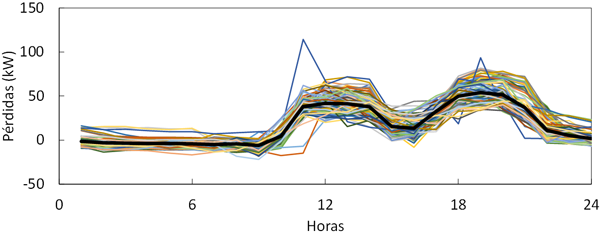
De la misma forma que el algoritmo k-means se emplea para crear patrones, también sirve para detectar patrones, ya que agrupa curvas similares.
Análisis de curvas históricas aplicando conocimiento de expertos
Un segundo conjunto de algoritmos se basa en la integración del conocimiento de expertos de detección de fraude, como se describe por ejemplo en [7]. Este conocimiento se ha traducido en una serie de reglas, para la detección de comportamientos sospechosos en las series temporales de los consumos de clientes. Por ejemplo, se identifican consumos intermitentes en los registros diarios. La regla en este caso sería:
- Si (horas consumo cero > 1) y (horas consumo cero < 23), entonces (ANOMALIA = 1).
Analizando un intervalo de datos en el pasado, por ejemplo el último año, se pueden detectar cambios de comportamiento y comprobar si este cambio coincide con un incremento en las pérdidas de la sub red. De esta forma, se aplica una nueva regla:
- Si (Anomalía (t) ≠ Anomalía (t-1) y (Pérdidas (t) > Pérdidas (t-1), entonces (Candidato = 1).
En el piloto se han implementado una serie de reglas, para demostrar su correcto funcionamiento. Una vez implementado en el BBT, está previsto incorporar más reglas. Mientras en la actualidad, este tipo de comprobaciones sobre datos históricos se están haciendo de forma rutinaria, el valor de esta aplicación consiste en la posibilidad de analizar la totalidad de los registros en muy poco tiempo. Dado que las comprobaciones de cada sub-red son independientes entre sí, el proceso es paralelizable y con eso, idóneo para una implementación en un sistema de Big Data. De esta forma, se consigue un resultado en tiempo real, a pesar del volumen considerable de datos.
Prueba piloto
Para comprobar los algoritmos, se ha creado un piloto con los datos históricos del 10% de los clientes de Viesgo desde septiembre 2015 (inicio del funcionamiento del BBT). Aunque el piloto es estático y trabaja sobre datos históricos, la estructura del mismo es tal que se facilita una implementación en el sistema de Big Data de Viesgo (IDbox [8]). El procedimiento consiste en la aplicación de los algoritmos al último año disponible de los datos para crear una lista de candidatos. En un primer paso se detectan los patrones de fraude y con ello los segmentos relacionados. Los segmentos detectados se cruzan con la base de datos, creando una lista de CUPS que existan en la sub-reden cuestión y pertenezcan a alguno de los segmentos detectados. Por ejemplo, si se detecta un patrón de fraude típico de un restaurante, en la lista se encuentran todos los restaurantes de esta sub-red. Para detectar algún CUPS en concreto muchas veces es necesario tener más indicios. Para ello se añade el análisis de los históricos, para detectar anomalías en la demanda individual. Finalmente, se comprueba de forma automatizada, si para los CUPS encontrados existe alguna alarma en el sistema. Tras cruzar todos estos datos, se obtiene la lista final de candidatos de fraude, que al final se comprueba en campo.
Plan de implementación
Tras comprobar el funcionamiento de los algoritmos, en esta última fase del proyecto se está diseñando la implementación en el BBT, basado en IDbox. Para el piloto, se creó una aplicación desconectada que enlaza una base de datos creada específicamente con ejecutables que contienen los algoritmos que se programaron en lenguaje Matlab. Para la implementación de los nuevos algoritmos en el BBT existente, será necesario integrar la base de datos del piloto y transcribir los algoritmos en lenguaje R. Mientras en el piloto se emplearon datos históricos, una vez implementados los nuevos algoritmos, el sistema de Big Data será capaz de realizar a diario una comprobación de la totalidad de las sub-redes de Viesgo. La rapidez de respuesta del seguimiento continuado de las pérdidas no técnicas es clave no sólo para minimizar las pérdidas sino también las acciones administrativas correctivas relacionadas.
Resultados obtenidos
Ejemplo de comportamientos sincronizados
En este caso el algoritmo detecta, en un día concreto, dos flags de interrupción de suministro registrados por el contador de uno de los clientes de la sub-red.

Este evento es coincidente en el tiempo con un aumento súbito de las pérdidas en la sub-red y con una disminución en los consumos del cliente.
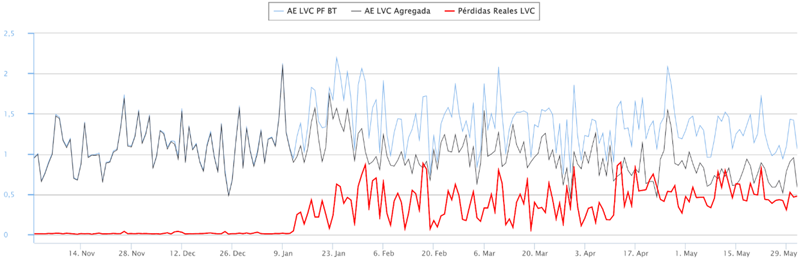
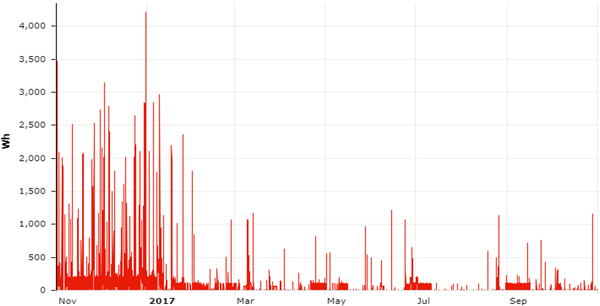
Demostrándose en la inspección in situ la existencia de una manipulación del contador.
Ejemplo búsqueda k-means
El algoritmo detecta una curva de pérdidas con un patrón característico de instalaciones de cultivo indoor. Se trata de ciclos de varios meses donde el primer mes aparecen pérdidas elevadas durante 16 horas/día, todos los días del ciclo, y en los siguientes meses las pérdidas se producen durante 12 horas/día, todos los días del ciclo.
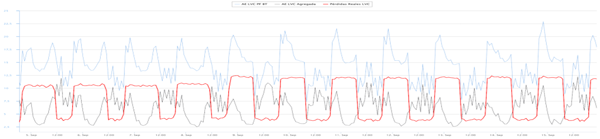
El algoritmo realiza una búsqueda e identifica ese patrón de consumo en uno de los Segmentos inventariados.
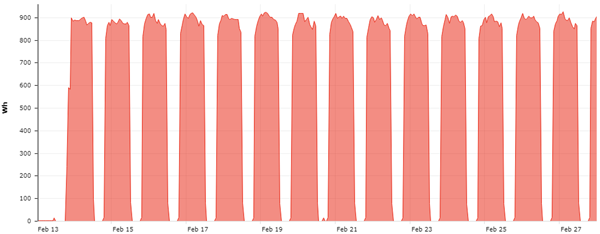
Esto permite dirigir la inspección en campo hacia los clientes de ese segmento y localizar el fraude.
Conclusiones
Los resultados de la prueba piloto sobre la muestra seleccionada han demostrado la validez de los procesos de segmentación, así como de los algoritmos de búsqueda. Estos resultados impulsan la aplicación del proyecto a la población completa de clientes en la red de Viesgo, así como la ejecución del plan de implantación previsto, que tiene por objetivo monitorizar de forma continua la evolución de las pérdidas en cada una de las sub-redes para detectar y corregir las anomalías con el mínimo tiempo de intervención reduciendo así las pérdidas no técnicas.
Referencias
- T. B. Smith, «Electricity theft: a comparative analysis,» Energy Policy, vol. 32, nº 18, pp. 2067-2076, 2004.
- G. López, J. Moreno, H. Amarís y F. Salazar, «Paving the road toward Smart Grids through large-scale advanced metering infrastructures,» Electric Power Systems Research, vol. 120, pp. 194-205, 2015.
- C. P. Herrero, «Big Data & Eficiencia Energética. Un nuevo modelo energético». [Último acceso: 2 10 2018].
- J. L. Viegas, P. R. Esteves, R. Melício, V. Mendes y S. M. Vieira, «Solutions for detection of non-technical losses in the electricity grid: A review,» Renewable and Sustainable Energy Reviews, vol. 80, pp. 1256-1268, 2017.
- R. Jiang, R. Lu, Y. Wang, J. Luo, C. Shen y X. Shen, «Energy-theft detection issues for advanced metering infrastructure in smart grid,» Tsinghua Science and Technology, vol. 19, nº 2, pp. 105-120, 2014.
- J. McQueen, «Some methods for classification and analysis of multivariate observations,» de Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Berkeley, 1967.
- J. I. Guerrero, C. León, I. Monedero, F. Biscarri y J. Biscarri, «Improving Knowledge-Based Systems with statistical techniques» Knowledge-Based Systems, vol. 71, pp. 376-388, 2014.
- IDbox, CIC Consulting Informático. [Último acceso: 2 10 2018].